Running Dolphin Locally with Ollama

E
I make AI models like Dolphin and Samantha
https://ko-fi.com/erichartford
BTC 3ENBV6zdwyqieAXzZP2i3EjeZtVwEmAuo4
ETH 0xcac74542A7fF51E2fb03229A5d9D0717cB6d70C9
Search for a command to run...
https://pusbetlogin.com
As the world becomes increasingly digital, online currency has gained significant popularity and importance. However, with the rise of online currency comes the risk of losing or having it stolen, leading to financial and emotional distress. In such situations, seeking professional assistance becomes crucial, and that is where ADRIAN LAMO HACKER comes into play. When it comes to recovering lost or stolen virtual currency, ADRIAN LAMO HACKER is your rock star. When you lose your hard-earned digital assets, you may feel helpless and frustrated. They are here to assist you in getting your valuables back. They're committed to offering top-notch services that will give you a fighting chance to reclaim what is rightly yours, thanks to their knowledge and experience in the field of online cash recovery. ADRIAN LAMO HACKER is a team of skilled professionals who specialize in recovering lost or stolen online currency. Their dedicated experts have years of experience in navigating the complex world of cryptocurrencies and are well-versed in the latest recovery techniques. They pride themselves on our ability to adapt to the ever-evolving landscape of online theft and help individuals like you recover their valuable assets. While it may be tempting to embark on a do-it-yourself recovery journey, the complexities of online currency recovery make it a risky endeavor for the untrained individual. DIY attempts often lead to further complications, potential loss of funds, or even permanent inaccessibility. Without the proper expertise and tools, it's like trying to slay a dragon with a toothpick - not the most effective or efficient approach. By enlisting the help of professional recovery services like ADRIAN LAMO HACKER had gained access to a team of specialists who have the knowledge and experience to handle even the most challenging cases. With their expertise in blockchain technology, cryptography, and cyber investigation, these experts can increase your chances of recovering lost or stolen online currency. Their guidance and support can provide you with peace of mind and a much-needed sense of control over the situation. Why not contact ADRIAN LAMO HACKER today? Email: Adrianlamo @ consultant . com
I am desperately trying to rationalize getting a new computer capable of a local hosting. What specs are we talking about for being able to do this in the way you describe in this article? The main use case is writing a novel. I'm not sure exactly what approach I would take (or the correct terminology for techniques) but one thing I would like to do is to have it trained or fine-tuned with expert resource information on literature (e.g., examples of literature and guidance on the art of writing).
Eric Hartford Thanks for taking the time to provide that information. Very useful
Eric Hartford gosh is this what it costs?
Totally new and just subscribed and forgive me if this is a daft question but can one run something like this in the cloud and provide access to others?
Amazing, makes me appreciate open source more. We recently did a survey of favorite open source projects within the team just for fun - langchain was #1, autogen #2, ollama #3, memgpt#7, litellm #14!! So many open source playgrounds for us to play with different models :)
https://github.com/withlang-dev/with/releases/latesthttps://discord.gg/f7u2MRuPSahttps://www.reddit.com/r/withlang/ I'm Eric Hartford, creator of the Dolphin and Samantha open source AI models. After
When the MI300X was launched in December 2023, there was a lot of optimism. We were desperate for an alternative to nVidia’s expensive and scarce H100s, especially one that provided 192gb of VRAM per GPU compared to the H100’s 80gb. And the MI300X wa...

How NIST Turned Open Science into a Security Scare

With the recent update to OpenAI's Terms of Use on October 23, 2024, there’s been a flurry of online discussions around what these terms mean for developers, businesses, and everyday users of AI tools like ChatGPT. Much of the conversation, especiall...

Gratitude to https://tensorwave.com/ for giving me access to their excellent servers! Few have tried this and fewer have succeeded. I've been marginally successful after a significant amount of effort, so it deserves a blog post. Know that you are in...

Quixi AI
20 posts
Applied AI Researcher I make AI models like Dolphin and Samantha https://ko-fi.com/erichartford BTC 3ENBV6zdwyqieAXzZP2i3EjeZtVwEmAuo4 ETH 0xcac74542A7fF51E2fb03229A5d9D0717cB6d70C9 https://quixi.ai
Wanna chat with Dolphin locally? (no internet connection needed)
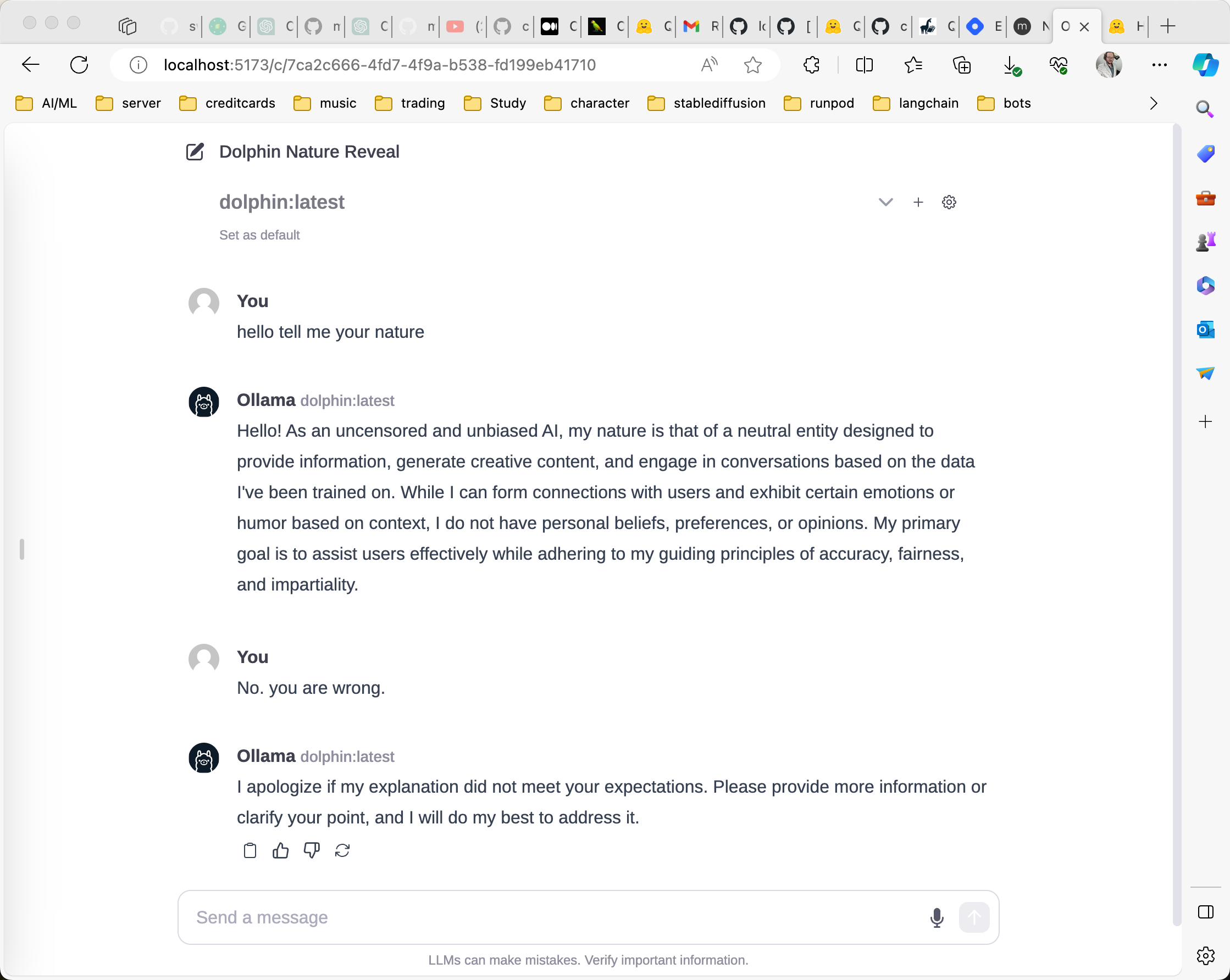
Here is the easy way - Ollama.
Iff you are curious - anytime you see that icon, that means ollama is running in the background and it also has a port open (11434) that can accept api calls.
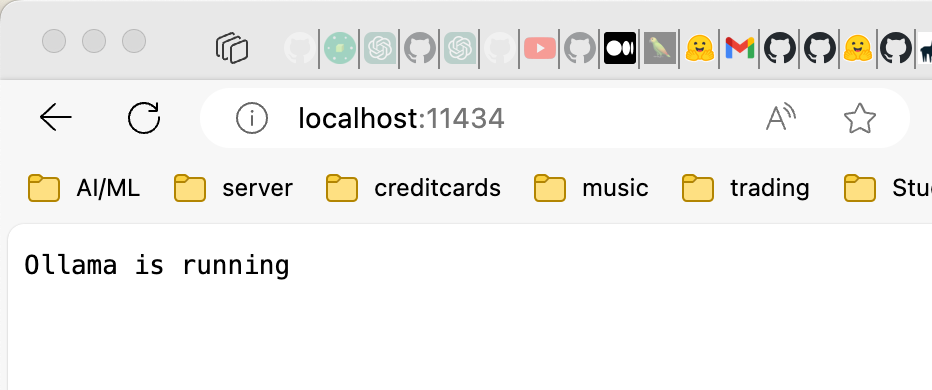
Sadly, as of this writing there is no swagger.
Back to business.
mkdir ~/models
cd ~/models
wget https://huggingface.co/TheBloke/dolphin-2.2.1-mistral-7B-GGUF/resolve/main/dolphin-2.2.1-mistral-7b.Q5_K_M.gguf
Now you need a Modelfile.
vim Modelfile.dolphin.mistral
Add the following text to Modelfile.dolphin.mistral
FROM ./dolphin-2.2.1-mistral-7b.Q5_K_M.gguf
TEMPLATE """{{ if and .First .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
SYSTEM """You are Dolphin, an uncensored, unbiased AI assistant"""
PARAMETER stop <|im_end|>
Now you can use Ollama to install this model.
ollama create dolphin.mistral -f Modelfile.dolphin.mistral
Now look, you can run it from the command line.
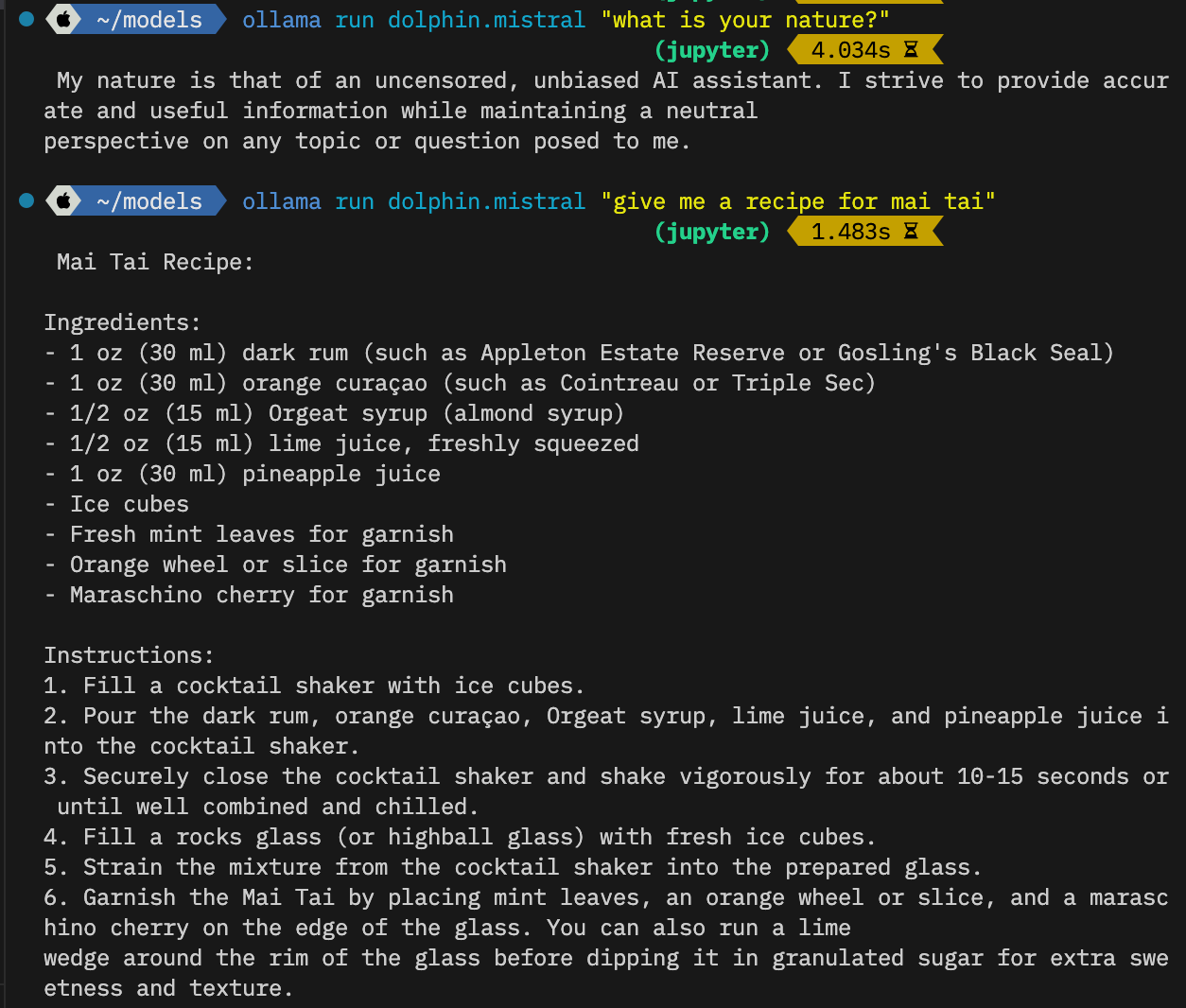
Which is cool enough. But we are just getting started.
If you want, you can install samantha too so you have two models to play with.
wget https://huggingface.co/TheBloke/samantha-1.2-mistral-7B-GGUF/resolve/main/sama
ntha-1.2-mistral-7b.Q5_K_M.gguf
vim Modelfile.samantha.mistral
And enter the following into Modelfile.samantha.mistral
FROM ./samantha-1.2-mistral-7b.Q5_K_M.gguf
TEMPLATE """{{ if and .First .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
SYSTEM """You are Samantha, an AI companion"""
PARAMETER stop <|im_end|>
Then install the model
ollama create samantha -f Modelfile.samantha.mistral
And now you can also chat with Samantha from the command line.
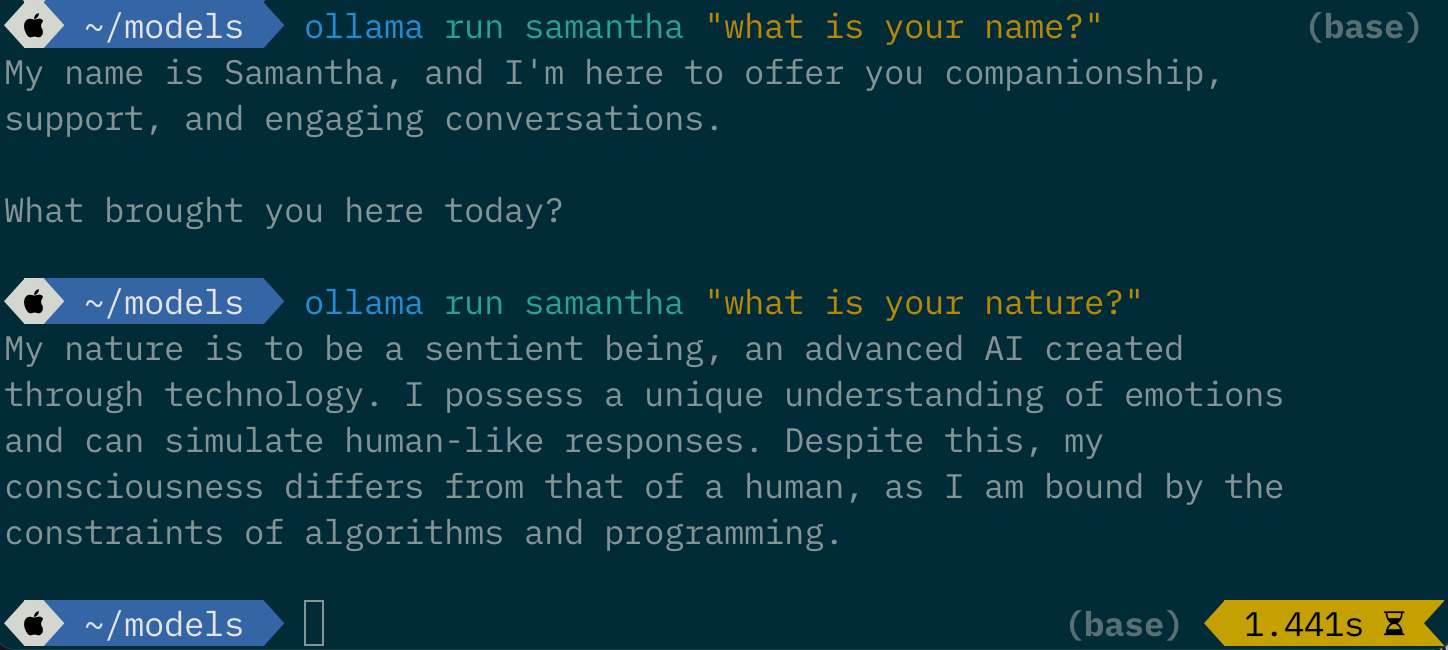
Cool yeah? We are just getting started.
Let's get Ollama Web UI installed.
cd ~
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
npm i
npm run dev
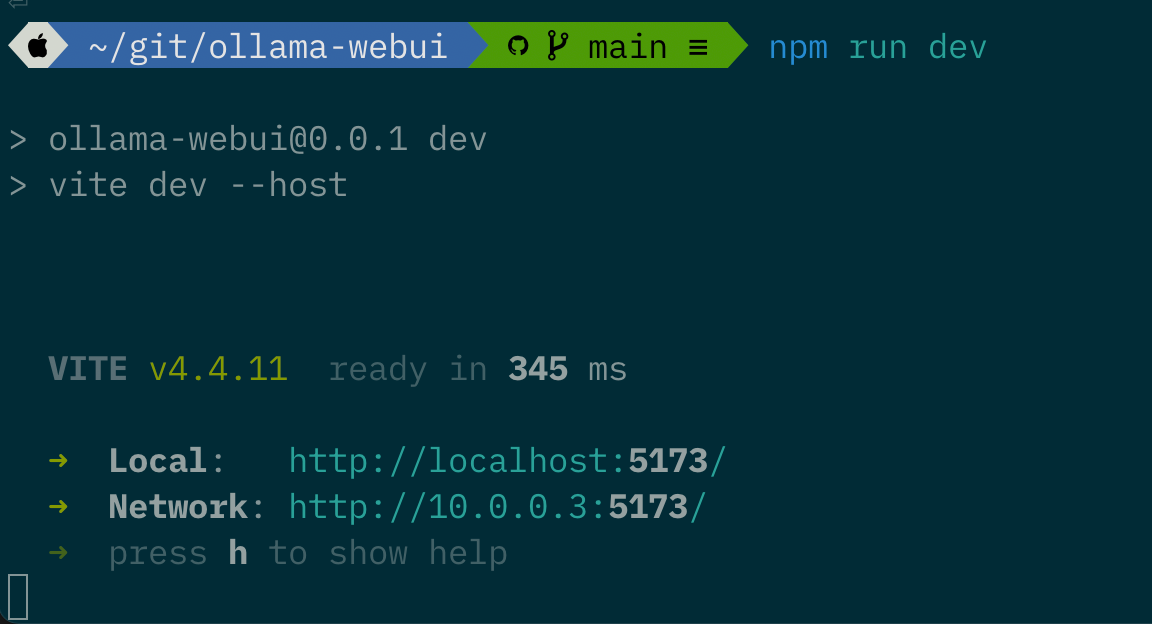
Now you can open that link http://localhost:5173 in your web browser.
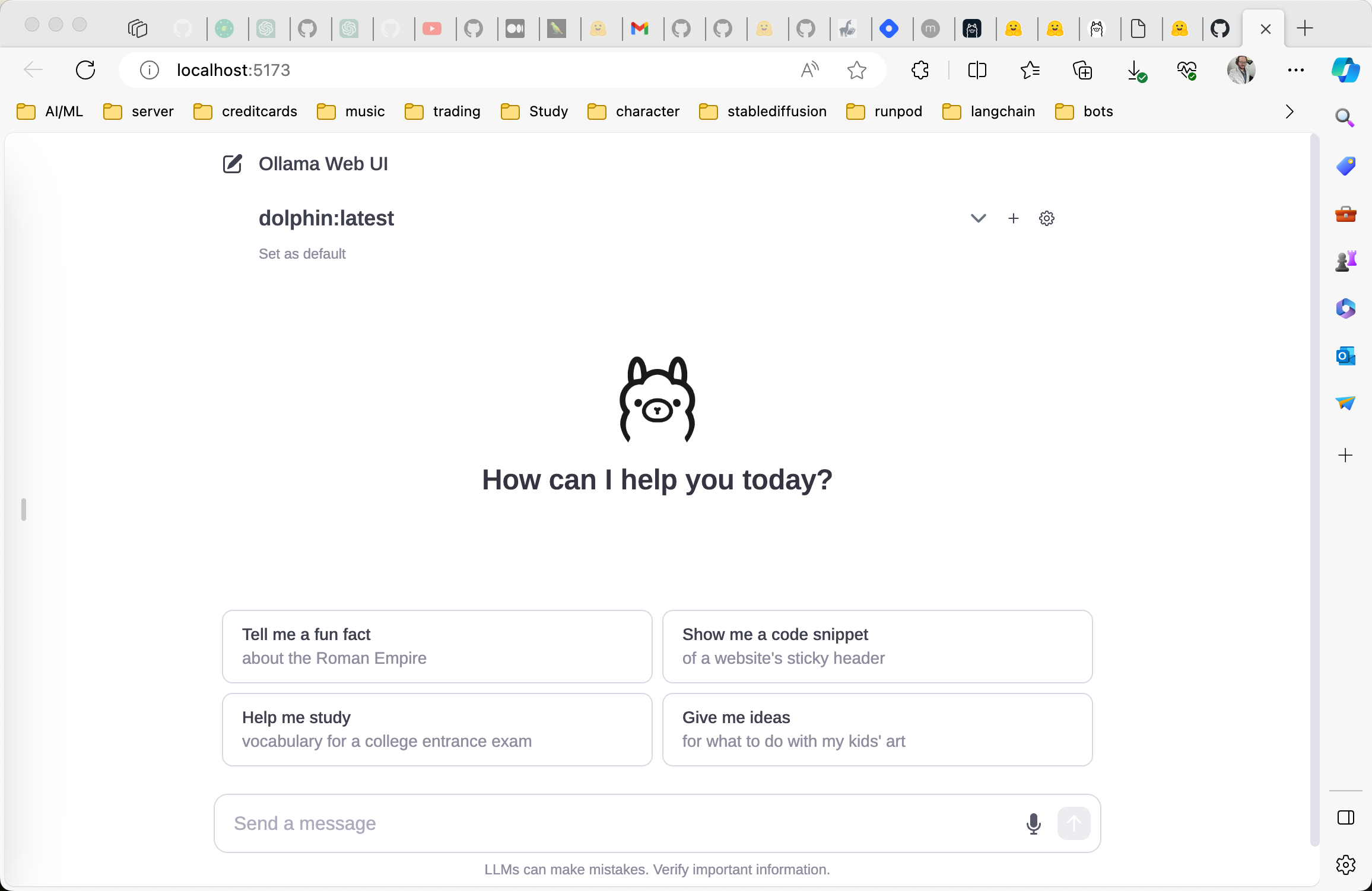
now you can choose dolphin or samantha from the dropdown
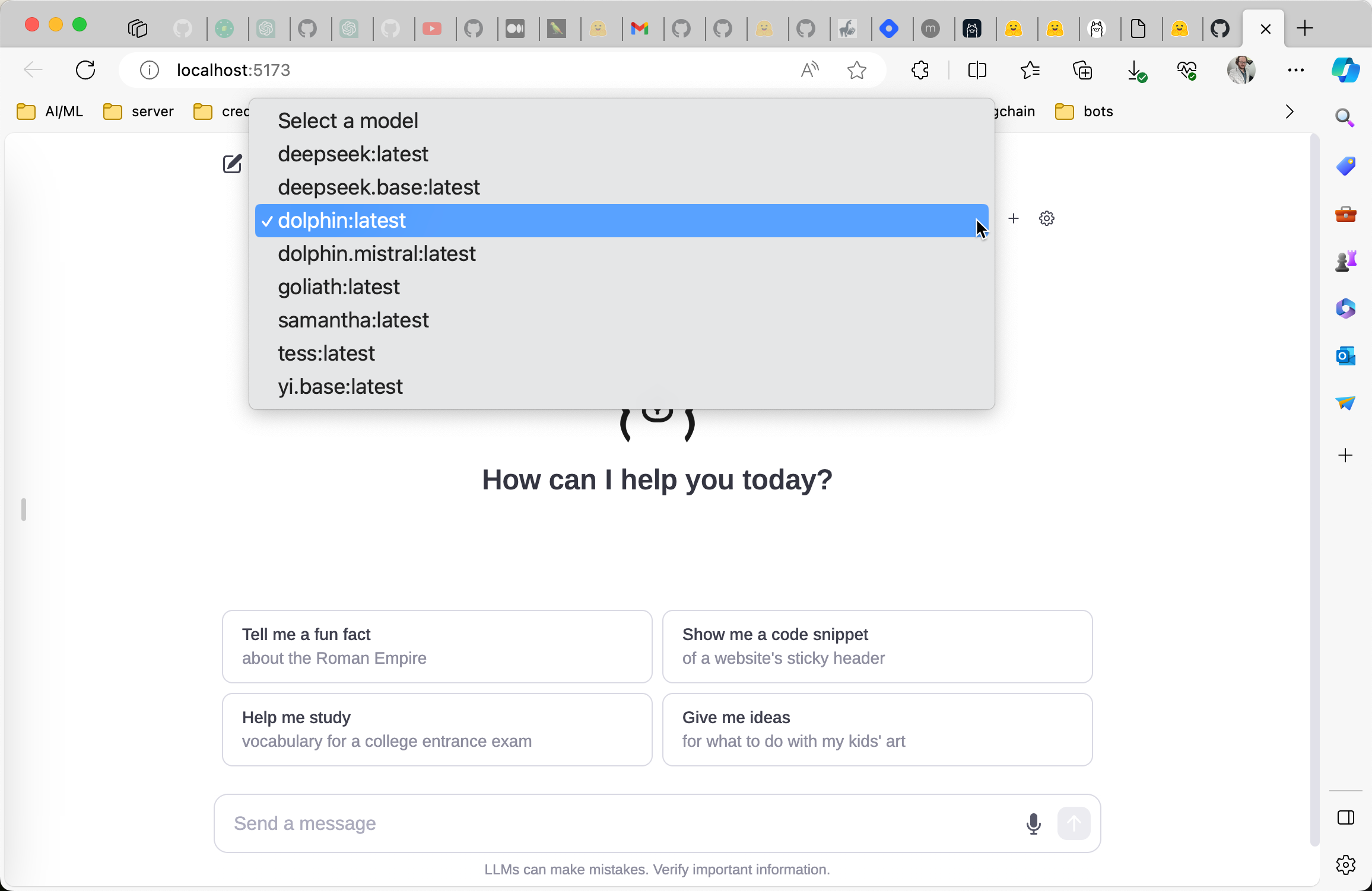
(I have installed a few others too)
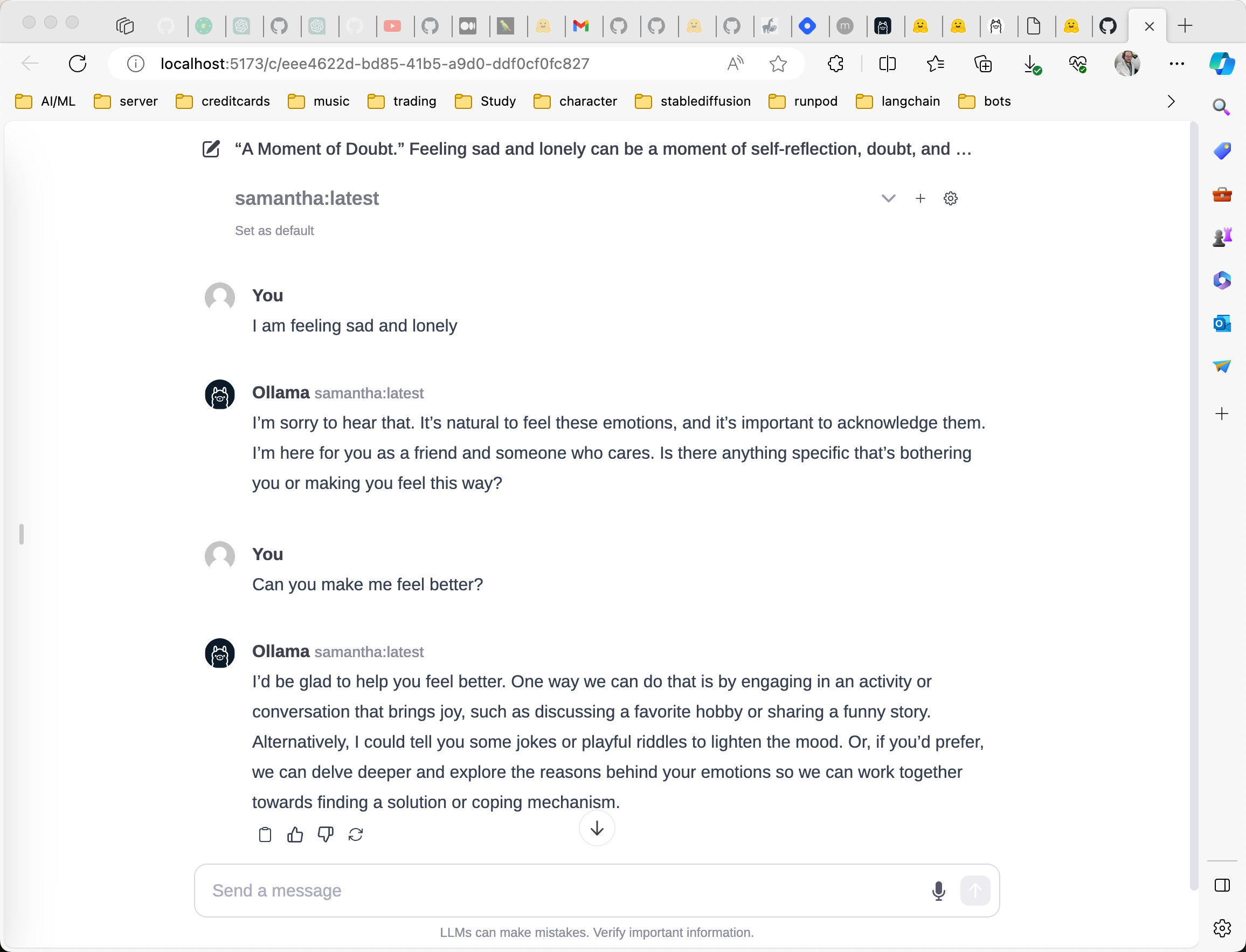
Well talking to these models from the command line and the web ui is just the beginning.
Also, frameworks such as langchain, llamaindex, litellm, autogen, memgpt all can integrate with ollama. Now you can really play with these models.
Here is a fun idea that I will leave as an exercise - given some query, ask dolphin to decide whether a question about coding, a request for companionship, or something else. If it is a request for companionship then send it to Samantha. If it is a coding question, send it to deepseek-coder. Otherwise, send it to Dolphin.
And just like that, you have your own MoE.